dba : the code is just an UDB translation of the 'whatever' script written in some 'whatever' interpreted language
programmer : well, that was my requirement, was asked to convert this into an db2 SP,
dba : whats the cardinality of this cursor ?
p : 72 million
d : (ok, today I did wake up in front of the mirror) and you think this is good?
p : that was the work set in the file for that script
d : do you know how that handled the file and memory? and do you know this is going to sort all 72 million rows?
p : so what? DB2 has been touted as best thing next to bread, should be a breeze, now you help me speed this up, is this locked?
d : (can't find a gun) hands out the 'thinking in sets' by joe celko can you please read this when free? (should contact Colbert, well there ain't colberts in the nerd domain )
p : ok, but promise you'll speed this procedure
d worked a week and came up with a procedure that worked in sets and wanted to advise this to the procedural DB programmer (along with the link to the famous 'kiss my royal irish a**' scene from 25th hour)
1. Databases are logical mappings of data, not physical, I've even been asked to run an update over one page to the next in the table, and table being called a file
2. projections and other db concepts rose out of set theory, so please think in sets,
3. break your work into finer pieces, the database and tables are not at your disposal
Once I was called to inspect a 'database slowness' for an SP. Below is a snippet.
declare cur1 cursor for select create_dt, client_cd,order_line_num from tab1 order by client_cd, create_dt ;
fetch cur1 into v_create_dt,v_client_cd,v_order_line_num;
if (completed(v_order_line_num,v_client_cd) = 1 )
then
do the processing for the client and for the particular line number;
.
.
end if;
set old_v_client_cd = v_client_cd;
set old_v_order_line_num = v_order_line_num;
while((fetch cur1 into v_client_cd,v_order_line_num) = (old_v_client_cd,old_v_order_line_num))
do
end while;
This sql was ordering 72 million rows and picking up the max date for a particular order line . Obviously the programmer wasn't updating his knowledge on the presence of the 'partition by' clause, so I re-wrote
update target_table1 set full_amt = (select sum(amt) from table1 t1 where row-number() over(partition by client_cd, order_line_num order by create_dt desc) = 1)
Simple and powerful single query to tackle a whole pseudocode. That is the power of set processing. Viola! the sp completed in 6 minutes compared to 4 hours and stopping the rest of the processes meanwhile.
I could go on and on about the 'legacy' data programmers, and 'architects'. I am not gifted to working with people like james koopman or Cunningham to have a great insight or implement architectures for the programs. But when I face these kinds of crap from programmers and team leads of over 10 years experience, I question whether it is their complacency or lack of the 'push' for improving their knowledge in the domain they work.
Regards to DB2, this has come a long way from a few blogs/a great info center to a thousand webpages, groups, conferences etc.
We were trying new stuff when we got a chance to work on a new BCU with 48 partitions, and awesome memory (8 GB per node), and tried using the MDC with all partitioning capabilities, in hashing and range. One of my colleagues used a variable high on cardinality and high on quantiles and no frequent values (DB2 terms). The load took more than 1 hour for a million rows, and it grew tremendously in size. Thus we started reading each and every line of the redbook
www.redbooks.ibm.com/redbooks/pdfs/sg247467.pdf
In my case, I used the year(order_thro_dt) and client_cd . So
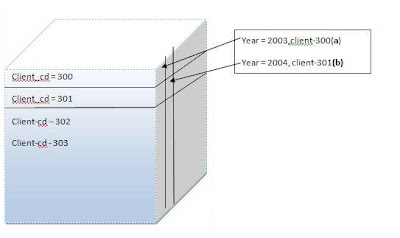
Client_cd = 300 Client_cd = 301 Client-cd – 302 Client-cd - 303 |
The cube gives you an ex if you use year and some frequently used value as dimentions,
The cube gives you an ex if you use year and some frequently used value as dimentions,
Imagine using ssn, the full 1st row in the violet will be for one ssn and one client, 2nd for one ssn and one client. Such a waste and such slow inserts since db2 has to ‘allocate the block when inserting every new value for the dimention’, so one per ssn – 123456789 and one when ssn = 234567890.
Now what happens during deletes is, db2 drops the whole block only when last value is deleted, for example , if we delete all instances of 300, the first row slice will go off(a), and if we delete all the year-2004 values, the 2nd column slice (b) will go off.
So the inserts of a new year like 2009 will make a case for new column dimention block to get created vis a vis new client for the row dimention block.
MDC and reorgs :
The reason why in case of MDC db2 would not need reorging is because the table is organized by dimensions, which are blocks, there will be only one pointer to the block, and not to every row of the table in case of normal indices.
Thus new blocks are added only when the existing ones get filled, for ex 300 has more than one extent of freq values, the 2nd block gets created. In this case, the 2nd and new block will have only one value and rest would all be empty. Thus the waste in space. So extent size or block size is very important in MDC since smaller blocks will make db2 create new ones, link with previous and take up higher cost, and larger ones waste space as given in the above example.
SQLs that can benefit from MDC :
Blocked indices could be thought of as a floor full of a class of people, one having only American citizens , one with Indian citizens and so on. The first row in the room will be filled with say people above 50 years, 2nd with people from 40-50 years , 3rd with people from 30-40 years.
Now if we want to know how many ‘Americans’ are above 50 years old, we just go to the top floor, and count everyone in the 1st row, end of story, and is the same case if we need count of just Indians, just go to the floor below the top and count the entire one.
So in our case, we have loads of sqls with predicates belonging to clients and the year of service,
Select sum(a), count(B) from table1 where client = ? and year_of_service= ?
This is a part of a typical OLAP query, and hence the assumption that mdc helps analysis queries and are not so helpful in transaction dbs where loading and deleting happens every day.
Now if we need to find someone by the name ‘thomas’, he could be an Indian, an American, a Chinese, and so db2 has to go to each floor and ask each guy if his name was Thomas – a very costly operation.
Select sum(a) from table1 where ssn = ?
For helping these kinds of queries, db2 allows normal indices along with MDC specification in a table.
Create index index1 on table1(ssn);
That will have pointers to each row with ssn value in the table. If it is unique, you can even create unique index, piggy back another non-unique column for ‘index only access’.
The above link to the redbook from IBM that gives you in depth review about MDC, when can they be considered, and the space calculation formulae. This entry was supposed to be a plain English introduction to this beautiful feature that can only be challenged by Oracle’s bit mapped index, but even then, DB2’s implementation wins hands down. The following link tells something about the deferred MDC rollout
This post was not aimed to be an indepth analysis or a strict tech post. So am not discussing about the mathematics of MDC considerations or size calculations. Please take a look at the DEFER value in the ’DB2_MDC_ROLLOUT’ variable and using it in SET CURRENT MDC ROLLOUT MODE statement.
I’ve always wanted db2 to have wider array of scalar functions.
Some like first day of month, last day of month are missing, but the most glaring one that many programmers use is the
max(val1,val2) = (val1 > val2, val1, val2),
and that is missing in UDB version 9.5 as of now. Not very sure about the latest 9.7 that boasts to save the world and solve the hunger problem though.
So I created one myself, and am heavily using it in my code so does other developers.
create function DB2ADMIN.MAXTWO(x date, y date)
returns date
begin atomic
if y is null or x >= y then return x;
else return y;
end if;
end;
Overload this for handling other datatypes and use them with descretion.
